
Avro Introduction
For streaming data use cases, Avro is a popular data serialization format. Avro is an open source data serialization system that helps with data exchange between systems, programming languages, and processing frameworks. Avro helps define a binary format for your data, as well as map it to the programming language of choice.
Avro relies on schemas. When Avro data is read, the schema is used and when writing it is always present. This permits each datum to be written with no per-value overheads, making serialization both fast and small. This also facilitates use with dynamic, scripting languages, since data, together with its schema, is fully self-describing.
Avro has a JSON like data model, but can be represented as either JSON or in a compact binary form. It comes with a very sophisticated schema description language that describes data.
Let us look at an example to represent the movie data below to Avro schema.
{
"imdbID": "tt0061722",
"Title": "The Graduate",
"Year": 1967,
"Director": "Mike Nichols",
"Actors": [
"Anne Bancroft",
"Dustin Hoffman",
"Katharine Ross",
"William Daniels"
],
"Language": "English",
"imdbRating": 8.1
}
Movie Avro Schema
Avro schema definitions are JSON records. Because it is a record, it can define multiple fields which are organized in a JSON array. Each such field identifies the field's name as well as its type. The type can be something simple, like an integer, or something complex, like another record.
In the movie schema we have defined the MovieDetails record type with associated fields to represent the movie data.
{
"type": "record",
"namespace": "com.stackstalk",
"name": "MovieDetails",
"fields": [
{
"name": "imdbID",
"type": "string"
},
{
"name": "Title",
"type": "string"
},
{
"name": "Year",
"type": "int"
},
{
"name": "Language",
"type": "string"
},
{
"name": "Director",
"type": "string"
},
{
"name": "Actors",
"type": {
"type": "array",
"items": {
"type": "string"
}
}
},
{
"name": "imdbRating",
"type": "float"
}
]
}
Confluent Platform
Confluent Platform is an enterprise grade distribution of Apache Kafka. It is a full-scale data streaming platform that enables you to easily access, store, and manage data as continuous, real-time streams. Each release of Confluent Platform includes the latest release of Kafka and additional tools and services that make it easier to build and manage an Event Streaming Platform.
For this example we will leverage confluent services zookeeper, broker, schema registry and control center as docker containers. Refer Confluent docker compose specs

Confluent Schema Registry enables safe, zero downtime evolution of schemas by centralizing the schema management. It provides a RESTful interface for storing and retrieving Avro, JSON Schema, and Protobuf schemas. Schema Registry tracks all versions of schemas used for every topic in Kafka and only allows evolution of schemas according to user-defined compatibility settings. This gives developers confidence that they can safely modify schemas as necessary without worrying that doing so will break a different service they may not even be aware of. Support for schemas is a foundational component of a data governance solution.
Confluent Control Center is a GUI-based system for managing and monitoring Kafka. It allows you to easily manage Kafka Connect, to create, edit, and manage connections to other systems. It also allows you to monitor data streams from producer to consumer, assuring that every message is delivered, and measuring how long it takes to deliver messages.
Python producer and consumer example using Confluent Kafka
Now let us write a simple producer and consumer to demonstrate the concepts discussed above. It is pretty simple with confluent kafka.
Let us focus on the producer first. This is an example of synchronous producer. Here we connect to the Kafka server on 9092 port and use the produce call to write a message to Kafka topic. We load the defined key and value Avro schema files and associate them during the Avro producer creation. We use the flush call to make the writes synchronous and to ensure the messages are delivered before the producer is shutdown.
#!/usr/bin/env python3
import json
from confluent_kafka import Producer, KafkaException
from confluent_kafka.avro import AvroProducer
from confluent_kafka import avro
def acked(err, msg):
if err is not None:
print("Failed to deliver message: %s: %s" % msg.value().decode('utf-8'), str(err))
else:
print("Message produced: %s" % msg.value().decode('utf-8'))
def load_avro_schema_from_file():
key_schema = avro.load("avro/movie-topic-key.avsc")
value_schema = avro.load("avro/movie-topic-value.avsc")
return key_schema, value_schema
def send_data():
producer_config = {
"bootstrap.servers": "localhost:9092",
"schema.registry.url": "http://localhost:8081"
}
key_schema, value_schema = load_avro_schema_from_file()
#print(key_schema)
#print(value_schema)
try:
producer = AvroProducer(producer_config, default_key_schema=key_schema, default_value_schema=value_schema)
f1 = open("data/movie-metadata.json", "r")
key_str = f1.read();
f1.close()
f2 = open("data/movie-details.json", "r")
value_str = f2.read()
f2.close()
producer.produce(topic = "movie-topic", key = json.loads(key_str), headers = [("my-header1", "Value1")], value = json.loads(value_str))
producer.flush()
except KafkaException as e:
print('Kafka failure ' + e)
def main():
send_data()
if __name__ == "__main__":
main()
Now let us write a simple consumer. We specify the Kafka server, schema registry and the consumer group as the configuration to create the Avro consumer. We subscribe to the topic of interest before going into a consume loop. In the consume loop we call the poll() method to retrieve the messages from the topic. If there are no messages then poll() method return None.
#!/usr/bin/env python3
import json
from confluent_kafka import Producer, KafkaException
from confluent_kafka.avro import AvroConsumer
from confluent_kafka import avro
def read_data():
consumer_config = {
"bootstrap.servers": "localhost:9092",
"schema.registry.url": "http://localhost:8081",
"group.id": "my-connsumer1",
"auto.offset.reset": "earliest"
}
#print(key_schema)
#print(value_schema)
consumer = AvroConsumer(consumer_config)
consumer.subscribe(['movie-topic'])
while True:
try:
msg = consumer.poll(1)
if msg is None:
continue
print("Key is :" + json.dumps(msg.key()))
print("Value is :" + json.dumps(msg.value()))
print("-------------------------")
except KafkaException as e:
print('Kafka failure ' + e)
consumer.close()
def main():
read_data()
if __name__ == "__main__":
main()
Run the producer code.
$ python3 producer.py
When you run the producer application we should see the messages being received by the consumer.
$ python3 consumer.py
Key is :{"imdbID": "tt0061722", "Title": "The Graduate"}
Value is :{"imdbID": "tt0061722", "Title": "The Graduate", "Year": 1967, "Language": "English", "Director": "Mike Nichols", "Actors": ["Anne Bancroft", "Dustin Hoffman", "Katharine Ross", "William Daniels"], "imdbRating": 8.100000381469727}
-------------------------
Key is :{"imdbID": "tt0061722", "Title": "The Graduate"}
Value is :{"imdbID": "tt0061722", "Title": "The Graduate", "Year": 1967, "Language": "English", "Director": "Mike Nichols", "Actors": ["Anne Bancroft", "Dustin Hoffman", "Katharine Ross", "William Daniels"], "imdbRating": 8.100000381469727}
-------------------------
Open the confluent control center http://localhost:9021/ to view the defined schema registered on movie topic.
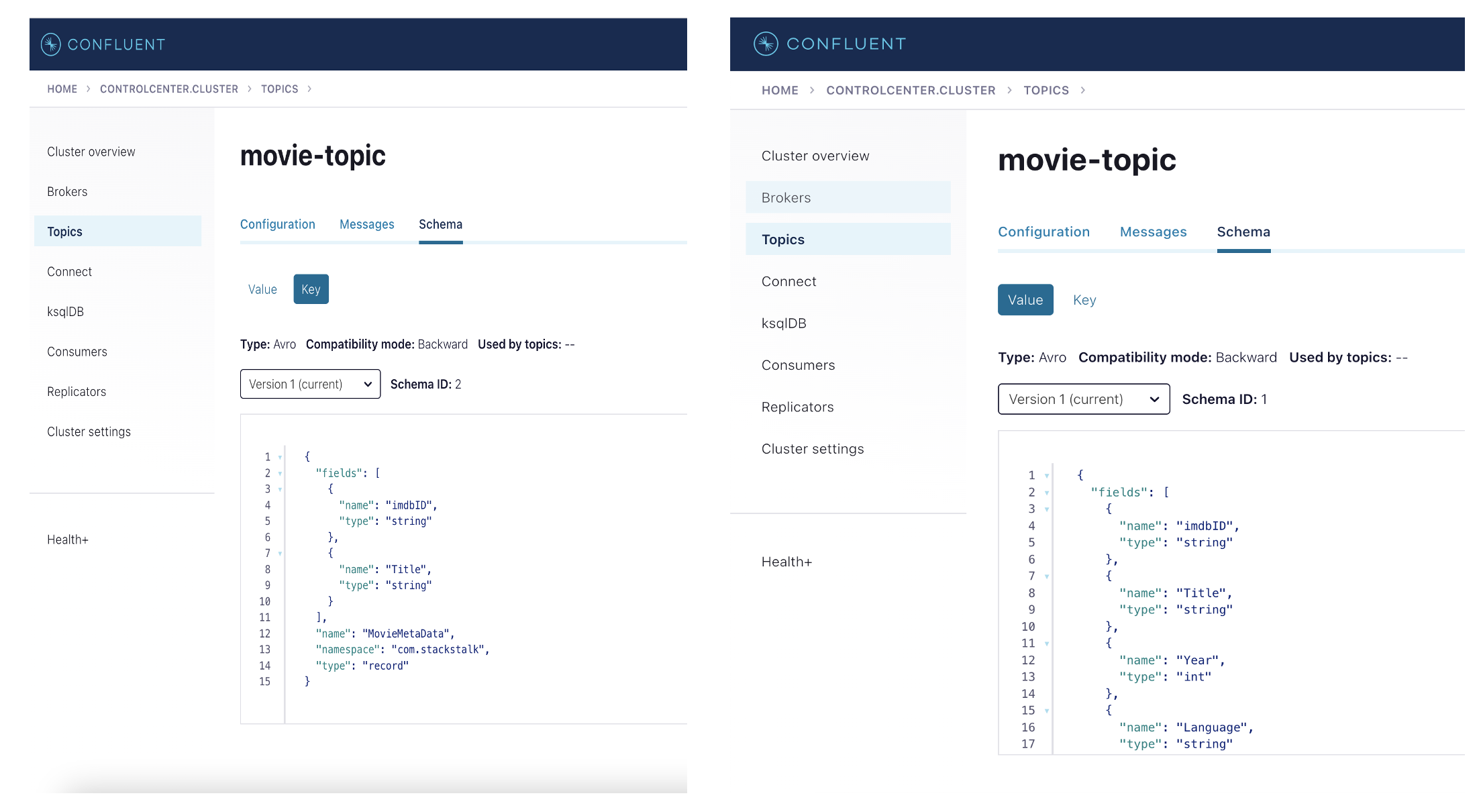
Get access to the source code of this example in GitHub.






0 comments:
Post a Comment